
Our tokenizer will perform one task – it will take a sequence of characters and emit a sequence of tokens. We will build it using an input stream from which the source characters are fetched, and then implement specific methods for reading from a string or from a file. When the tokenizer has read a complete token, it will generate an event passing along the token. The actual rules for what constitutes a valid token may differ. If we parse the text of a novel, we may consider each word a token, or maybe each sentence. If we parse source code, we may have different rules depending on the language we want to parse. We may have a lot of different rules, and we will call such a rule a tokenization.
Now, in the last post, I promised a tokenizer that, among other things, could eliminate comments. For the sake of clarity, I have decided to start with a few simpler tokenizers that will show the basics, and we may get back to a more complex tokenizer in a later project.
In our project, this “read characters from an input stream and generate token events” functionality will be implemented by an object of type TTokenizer. The actual tokenization rule will be implemented by a class deriving from the TTokenization class. We could have created a base TTokenizer class and then derived from that class to implement specific rules, but by splitting it up this way, we will probably get a more flexible design. Assume for instance that you have your own logging system, and you wish to create a logging tokenizer. With our approach, all you have to do is derive from TTokenizer, creating e.g. a TLoggingTokenizer class, and use it regardless of the actual tokenization that you will be using.
You can download the source code for this project here. The following picture shows the relationship between our classes, and hints at the tokenization objects we will create:
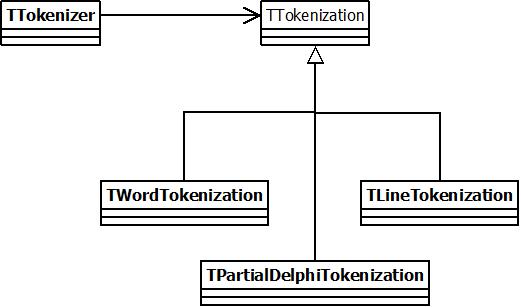
The interface of TTokenization is shown below:
TTokenization = class
private
FCurrentLine: Integer;
protected
CurrentToken: String;
procedure AddToToken(C: Char);
procedure IncreaseLine;
procedure DoToken(HandleToken: TTokenHandler; C: Char);
public
property CurrentLine: Integer read FCurrentLine;
procedure Initialize; virtual;
function ProcessCharacter(C: Char; HandleToken: TTokenHandler;
var Reverse: Integer): Boolean; virtual; abstract;
end;
The ProcessCharacter method is called for each character read by the tokenizer. In the TTokenization class, it is declared as an abstract method, and it must be overridden in any inherited class. If the tokenization object has read a complete token, it should call the HandleToken method. If it encounters an invalid token, it should return False. If it encounters an unexpected token, but realizes that there may be a way to re-parse some of the characters, it should set the Reverse parameter to the number of characters it wants the stream reversed before the next call to ProcessCharacter, and return True.
The Initialize method is called by the tokenizer before it starts consuming characters from the input stream. In the base class, Initialize simply set FCurrentLine to 1 and clears CurrentToken, but a derived class may need to perform additional initialization. We will see later how the “partial delphi” tokenization class does this.
Derived classes may use the AddToToken method, which adds the given character to the current token, and the DoToken method, which will call the HandleToken method, supplying the current token, if the token is not empty, and then clear the token. It will also increase the current line number if the character is #10 (newline).
The most important method of TTokenizer is Process, which handles the tokenization of a stream of characters:
function TTokenizer.Process(S: TStream; T: TTokenization;
HandleToken: TTokenHandler): Boolean;
var
C: Char;
R: Integer;
begin
Result := True;
if Assigned(HandleToken) then
begin
R := 0;
T.Initialize;
S.Seek(0, soBeginning);
while S.Position < S.Size do
begin
S.Read(C, SizeOf(Char));
if not T.ProcessCharacter(C, HandleToken, R) then
begin
FErrorLine := T.CurrentLine;
Result := False;
Exit;
end
else if R <> 0 then
begin
S.Seek(-R, soFromCurrent);
R := 0;
end;
end;
T.ProcessCharacter(#0, HandleToken, R);
end;
end;
The Process method takes a stream from which is consumes characters, a tokenization object determining the rules, and a pointer to a method that should be called when a complete token has been read. It is basically a loop that consumes characters until it reaches the end of the stream. Each character is fed into the tokenization object’s ProcessCharacter method, so that it can be handled properly. If the ProcessCharacter method returns False, the tokenization ends. In this case, the tokenizers’s ErrorLine property indicates on which line in the input the error occurred. The tokenization object may also indicate that it wants to reverse the position in the stream (i.e. re-read one or more characters) by setting its Reverse parameter to a value different from zero. We will see an example of this later.
To explain the different tokenizations, we will create four of them. We will start with the TLineTokenization class, which will regard each line as a single token. We will then create TWordTokenization, which will split up the input into separate words, and separators. We will then create TStringEvaluatorTokenization, which is the one we will actually use in our “string evaluator”, which will be explained in the next post. We will also take a look at a tokenizer for Delphi code, which can correctly handle e.g. “<=" as a separate token (where the word tokenizer would regard "<=" as two tokens).
The TLineTokenization class is the simplest one – all we need to do is override the ProcessCharacter to emit a token when a complete line has been read:
function TLineTokenization.ProcessCharacter(C: Char;
HandleToken: TTokenHandler; var Reverse: Integer): Boolean;
begin
if C in [#0, #10, #13] then
DoToken(HandleToken, C)
else
AddToToken(C);
Result := True;
end;
We emit a line when we encounter a #13 (carriage return) or a #10 (newline) or a #0 (end of input). Note that this will work both for input that separates its lines using #13 and #10 (e.g. Windows) and input that separates its lines using only #10 (e.g. Unix). In the Windows case, we will call DoToken to emit a token when we encounter the #13, and then we will call DoToken again when we encounter #10. This time, however, the current token is empty so the HandleToken method is not called again, since that is how the DoToken method is implemented.
TWordTokenization is not much more complicated – it introduces punctuators, which are complete tokens in themselves – when one is encountered, it is immediately treated as a token.
const
Punctuations = ['.', ',', ';', ':', '(', ')', '{', '}', '[', ']', '!',
'?', '=', '<', '>', '+', '-', '*', '/'];
function TWordTokenization.ProcessCharacter(C: Char;
HandleToken: TTokenHandler; var Reverse: Integer): Boolean;
begin
if C in [#0, #10, #13, ' '] then
DoToken(HandleToken, C)
else if C in Punctuations then
begin
DoToken(HandleToken, C);
AddToToken(C);
DoToken(HandleToken, C);
end
else
AddToToken(C);
Result := True;
end;
TStringEvaluatorTokenization is the first tokenization that introduces state, i.e. which may handle a character differently depending on what it is currently parsing. The following state diagram describes the different states, and how characters are handled:
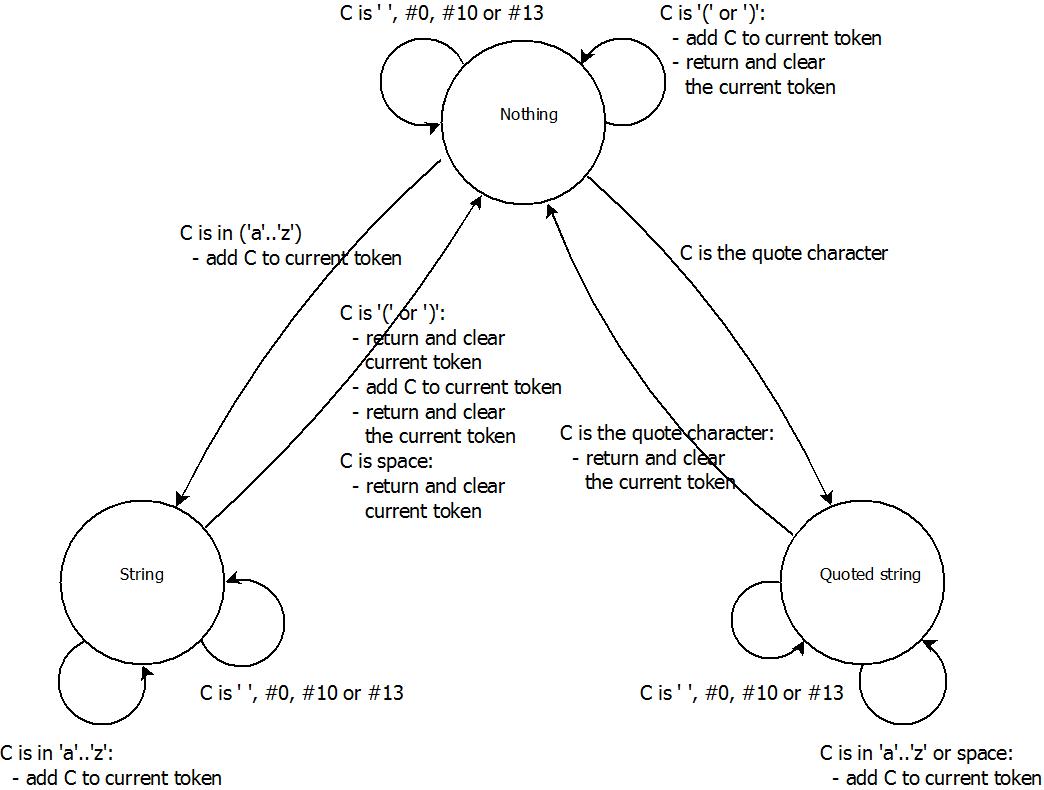
When we read the first token, we are in state “parsing nothing”. If the character read is “(” or “)”, it should be treated as a separate token, and we consider it as such, passing the token along oto the user and staying in the state “parsing nothing”. If we read a quote character, this indicates that we should start parsing a quoted string, so we enter that state (and drop the quote character, since it is not part of the string). Any other valid character (for simplicity we allow only the letters “a” – “z”, in upper or lower case) takes us to the “parsing string” state. In this case, the character read is the first chjaracter of the string, so we add it to the current token. Any other character read in this state is an error.
In the state “parsing quoted string”, there are three cases. If we read a quote character we know that we have read the whole string, so we pass it along to the user. We drop the quote character, since it is not part of the string, and go to state “parsing nothing”. If we read any valid character (including the space character; this is the main reason for using a quoted stering), we add it to the current token and remain in the “parsing quoted string” state. Any other character is an error.
If, in the state “parsing string”, we read “(” or “)”, we first consider the current token to be finished, and we pass it along to the user. When then treat the character as a separate token, and we pass it along to the user and go to the state “parsing nothing”. This means that if we e.g. read “and(“, we will consider “and” to be a token and “(” to be another. In the “parsing string” state, the space character is used to separate tokens, so if we encounter it, we pass along the current token to the user, drop the space character and go to state “parsing nothing”. If we read any other valid character, we add it to the current token, and remain in the “parsing string” state. Any other character is an error.
What we have looked at so far is all we need to know for the string evaluator project. I want to highlight one point at this stage though. The tokenizations we have created so far are “predictive”. This means that as soon as we read a character, we know what to do with it. If we were to create a parser for the Delphi language however, we would run into a problem with this approach. Assuming that we want the Delphi tokenization rule to differ between the “data type operator” (:) and the assignment operator (:=). When we have read the “:”, we still don’t know what to do with it. If the next character is a “=”, we have no problem and we can pass the token “:=” to the user. If the next character is “I”, such as it might be in the declaration “i:Integer;”, we know that we should have sent along the “:” to the user, and the next token should begin with “I”. At this point we may generate the “:” to the user, and tell the tokenizer to reverse one step, before continuing. The TPartialDelphiTokenization class uses this to be able to parse Delphi code. I have decided to call this tokenization class TPartialDelphiTokenization to stress that it parses only some parts of the Delphi language – more specifically integers, identifiers and some operators and separators. If you want to see how this is accomplished, have a look in the source code.